With the introduction of the for-each activity in Databricks workflows in August 2024, this orchestration service has become much more flexible. This could become a viable alternative or addition to for example Azure Data Factory, as the integration with Databricks couldn’t get any easier.
This article describes a way to run nested workflows in Databricks using for-each loops. In my example and use case I use metadata in json format and two workflows: Nested_Workflow_Parent & Nested_Workflow_Child. The result of the final workflow will look like this:
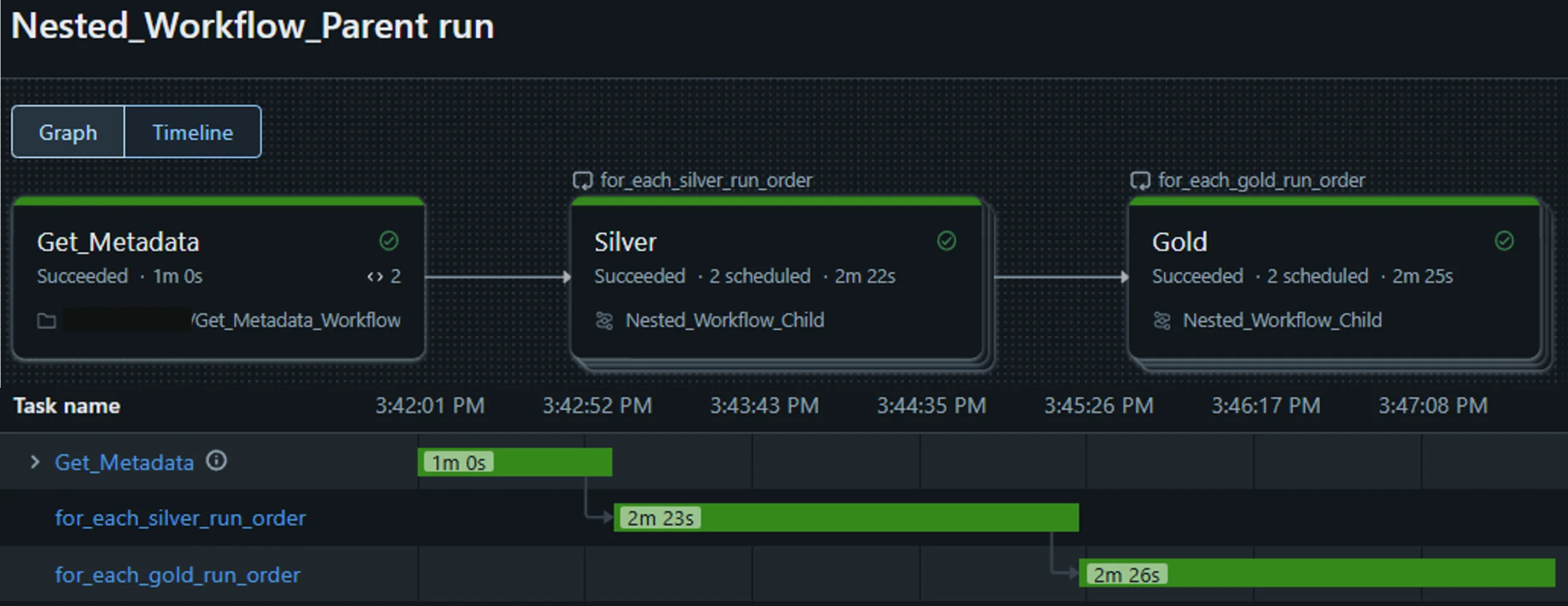
Consider the following scenario: You want to run notebooks for each medallian layer in a particular order. I will call this order „run_order“. For example, in the gold layer you might want to run all the dimension notebooks first, then all the fact notebooks. Or in the silver layer you might want to be able to prioritise the load by country or year. Here is some example data and the code to create the dataframe called df_input.

from pyspark.sql import functions as F
from pyspark.sql.types import StructType, StructField, StringType, IntegerType
schema = StructType([
StructField("task", StringType(), True),
StructField("layer", StringType(), True),
StructField("run_order", IntegerType(), True),
StructField("notebook_parameter", StringType(), True),
StructField("notebook_path", StringType(), True)
])
# Create the DataFrame
data = [
("MyTask", "silver", 1, '{"CountryCode": "DE", "YYYY": "2024"}', "/path/to/silver_notebook1"),
("MyTask", "silver", 1, '{"CountryCode": "FR", "YYYY": "2024"}', "/path/to/silver_notebook1"),
("MyTask", "silver", 2, '{"CountryCode": "DE", "YYYY": "2023"}', "/path/to/silver_notebook1"),
("MyTask", "silver", 2, '{"CountryCode": "FR", "YYYY": "2023"}', "/path/to/silver_notebook1"),
("MyTask", "gold", 1, '{"DefaultParm":"NA"}', "/path/to/gold_fact_notebook"),
("MyTask", "gold", 2, '{"DefaultParm":"NA"}', "/path/to/gold_dim1_notebook"),
("MyTask", "gold", 2, '{"DefaultParm":"NA"}', "/path/to/gold_dim2_notebook"),
("MyTask", "gold", 2, '{"DefaultParm":"NA"}', "/path/to/gold_dim3_notebook")
]
columns = ["task", "layer", "run_order", "notebook_parameter", "notebook_path"]
df_input = spark.createDataFrame(data, columns)
df_input.display()
Next, let’s define more precisely which steps can be performed in parallel and which must be performed sequentially:

The first step is to create the metadata. The source dataframe (df_input) holds the infomartion about the task name, the layer and the run_order per layer. The table granularitity is notebook_path and notebook_parameter.
Workflows require a json as input. Because of this it is necessary to transform the source metadata dataframe to nested json’s „with two layers“ – One per layer. The resulting outputs will be json formatted lists, silver_out and gold_out. These are saved as Databricks task using „dbutils.jobs.taskValues.set“ values so they can be used the next tasks of the workflow. Here are two variants of the code to generate the lists out of the dataframe and a visual representation of the json.

# Code variant 1
from pyspark.sql import functions as F
import json
def process_meta_layer_v1(df_meta, layer_name):
# Filter dataframe to one layer
df_layer = df_meta.filter(F.col("layer") == layer_name).orderBy(F.col("run_order"))
# Group by run_order and collect items as a nested list
nested_json_df = (
df_layer.groupBy("run_order")
.agg(
F.collect_list(
F.struct(
F.col("task"),
F.col("layer"),
F.col("run_order"),
F.col("notebook_parameter"),
F.col("notebook_path")
)
).alias("items")
)
.select(
F.col("run_order"),
F.col("items")
)
.orderBy("run_order")
)
# Convert to JSON structure
result_json = nested_json_df.select(
F.to_json(F.struct(F.col("run_order"), F.col("items"))).alias("nested_json")
)
# Collect JSON strings and parse into Python dictionaries
parsed_output = [
json.loads(row["nested_json"])
for row in result_json.collect()
]
# Pretty-print the parsed output
print(f"{layer_name}_out:\n {json.dumps(parsed_output, indent=3)} \n")
# Create Databricks task value
dbutils.jobs.taskValues.set(key=f'{layer_name}_out', value=parsed_output)
process_meta_layer_v1(df_input, 'silver')
process_meta_layer_v1(df_input, 'gold')
# Code variant 2
from pyspark.sql import functions as F
import json
def process_meta_layer_v2(df_meta, layer_name):
# Collect the dataframe sorted by run_order
layer_list = df_meta.filter(F.col("layer") == layer_name).orderBy("run_order").collect()
# Organize data by run_order as outer layer
parsed_output_v2 = []
current_order = None
current_group = {}
for x in layer_list:
order = x['run_order']
if order != current_order:
# Append the previous group if it exists
if current_group:
parsed_output_v2.append(current_group)
# Initialize a new group for the current order
current_group = {
'run_order': order,
'items': []
}
current_order = order
# Add the current item to the current group
current_group['items'].append({
'task': x['task'],
'layer': x['layer'],
'run_order': x['run_order'],
'notebook_parameter': x['notebook_parameter'],
'notebook_path': x['notebook_path']
})
# Append the last group to the main output
if current_group:
parsed_output_v2.append(current_group)
# Pretty-print the parsed output
print(f"{layer_name}_out:\n {json.dumps(parsed_output_v2, indent=3)} \n")
# Set the structured data to a Databricks task value
dbutils.jobs.taskValues.set(key=f'{layer_name}_out', value=parsed_output_v2)
return parsed_output_v2
# Process for silver, gold and platinum layer
silver_out = process_meta_layer_v2(df_input, 'silver')
gold_out = process_meta_layer_v2(df_input, 'gold')
Start with the Child workflow before building the parent one. Otherwise you will need to jump from one to the other. Create a job parameter, call it „item_parameter“. It will hold all item (=notebook) information.


resources:
jobs:
Nested_Workflow_Child:
name: Nested_Workflow_Child
tasks:
- task_key: Execute_each_Notebook
for_each_task:
inputs: "{{job.parameters.item_parameter}}"
concurrency: 20
task:
task_key: Execute_Notebooks_iteration
notebook_task:
notebook_path: /Workspace/Users/tbd/Execute_Notebooks
base_parameters:
task: "{{input.task}}"
notebook_parameter: "{{input.notebook_parameter}}"
notebook_path: "{{input.notebook_path}}"
layer: "{{input.layer}}"
run_order: "{{input.run_order}}"
source: WORKSPACE
min_retry_interval_millis: 900000
disable_auto_optimization: true
min_retry_interval_millis: 900000
queue:
enabled: true
parameters:
- name: item_parameter
default: ""
For the matadata task, use the „Notebook“ type and link the notebook which reads or creates the metadata and transforms it into json. Verify you make the output available as task value for subsequently tasks using „dbutils.jobs.taskValues.set„.
Now create as many for-each tasks as many layers you have, in this case 2:
resources:
jobs:
Nested_Workflow_Parent:
name: Nested_Workflow_Parent
tasks:
- task_key: Get_Metadata
notebook_task:
notebook_path: /Workspace/Users/tbd/Get_Metadata_Workflow
source: WORKSPACE
min_retry_interval_millis: 900000
disable_auto_optimization: true
- task_key: for_each_gold_run_order
depends_on:
- task_key: for_each_silver_run_order
for_each_task:
inputs: "{{tasks.Get_Metadata.values.gold_out}}"
concurrency: 1
task:
task_key: Gold
run_job_task:
job_id: 123456
job_parameters:
item_parameter: "{{input.items}}"
- task_key: for_each_silver_run_order
depends_on:
- task_key: Get_Metadata
for_each_task:
inputs: "{{tasks.Get_Metadata.values.silver_out}}"
concurrency: 1
task:
task_key: Silver
run_job_task:
job_id: 456789
job_parameters:
item_parameter: "{{input.items}}"
queue:
enabled: true